Jupyter Notebooks
Objectives
Know what it is
Create a new notebook and save it
Open existing notebooks from the web
Be able to create text/markdown cells, code cells, images, and equations
Know when to use a Jupyter Notebook for a Python project and when perhaps not to
[this lesson is adapted from https://coderefinery.github.io/jupyter/motivation/]
Jupyter is one of multiple options for executable notebooks (other RMarkdown, Pluto). Often used in teaching.
Motivation for Jupyter Notebooks

One of the first notebooks: Galileo’s drawings of Jupiter and its Medicean Stars from Sidereus Nuncius. Image courtesy of the History of Science Collections, University of Oklahoma Libraries (CC-BY).
Code, text, equations, figures, plots, etc. are interleaved, creating a computational narrative.
The name “Jupyter” derives from Julia+Python+R, but today Jupyter kernels exist for dozens of programming languages.
Note
Understanding the Jupyter architecture
It is important to understand how Jupyter Notebooks work behind the scenes. Here’s a simple way to think about it:
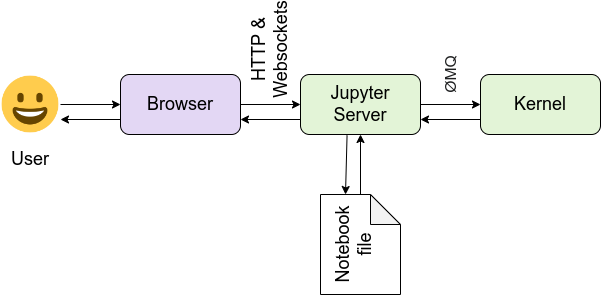
Together, this setup allows you to write code, execute it, and see results — all in one place!
This is a simplified view — in practice, the Jupyter architecture can be extended with multiple users, remote kernels, and more. See the full architecture documentation at https://docs.jupyter.org/en/latest/projects/architecture/content-architecture.html
Jupyter Notebook: One notebook file in your browser Jupyter Lab: Workspace for notebooks, terminal other files, extensions etc
Both of above you can install and run on your own computer or in the cloud.
Jupyter Hub: Multi user self-hosting option (your institution might host their own)
What is Noppe?
Noppe (previously CSC Notebooks) offers web applications (RStudio and Jupyter) for self-learning, hosting courses and collaboration. The applications are accessed through a web browser and run in CSC cloud.
Use cases for notebooks
Really good for step-by-step recipes (e.g. read data, filter data, do some statistics, plot the results)
Experimenting with new ideas, testing new libraries/databases
As an interactive development environment for code, data analysis, and visualization
Keeping track of interactive sessions, like a digital lab notebook
Supplementary information with published articles
Good practices
Run all cells or even Restart Kernel and Run All Cells before sharing/saving to verify that the results you see on your computer were not due to cells being run out of order.
This can be demonstrated with the following example:
numbers = [1, 2, 3, 4, 5]
arithmetic_mean(numbers)
We can first split this code into two cells and then re-define numbers
further down in the notebook. If we run the cells out of order, the result will
be different.
Limitations of notebooks
(Read more at Pitfalls of Jupyter Notebooks.)
You can run cells in any order, which may lead to confusing or incorrect results if you’re not careful.
Variables stay in memory even if you delete the cell that created them — this can lead to surprises!
Hard to know what’s been run and in what order unless you restart the kernel and run all cells.
Notebooks don’t by default work well with version control (like Git) because output cells can make the files messy.
Mixing too much text, code, and results can make notebooks hard to read or maintain if they get too long.
Notebooks aren’t ideal for building reusable scripts, libraries, or production code — they are more for exploration.
If you’re using notebooks for more than quick experiments or interactive work, it’s good to be aware of these limitations — and consider moving parts of your workflow to regular .py files when needed.
Keypoints
Jupyter Notebooks combine code, text, plots, and results in one document: ideal for interactive data exploration.
Use markdown cells for documentation and code cells for execution.
Always restart and run all cells before sharing or saving to avoid confusion from out-of-order execution.
Notebooks are great for exploration, teaching, and prototyping, but not the best tool for large software projects or version-controlled pipelines.
Watch out for common pitfalls like hidden variables, confusing outputs, and version control issues.